最近想玩玩 CUDA programming,以下是一些收集到的資料,先筆記一下。我使用Visual Stidio 2015來開發,安裝時須順便安裝Windows10 SDK:
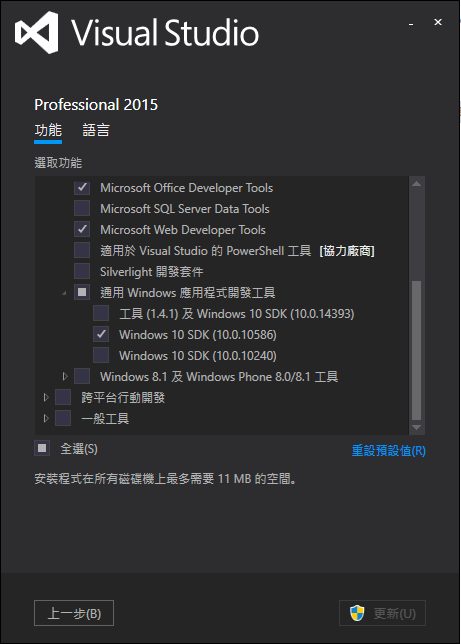
安裝好VS2015後,到https://developer.nvidia.com/cuda-downloads 下載 CUDA Toolkit,現在最新版本是CUDA SDK 9,但我實作時安裝的是CUDA 8。安裝時可指定目錄,預設Toolkit安裝目錄為C:\Program Files\NVIDIA GPU Computing Toolkit,另外將範例程式Samples安裝到其他目錄。安裝完成後,會在VS2015上方選單多一個NSight選項:
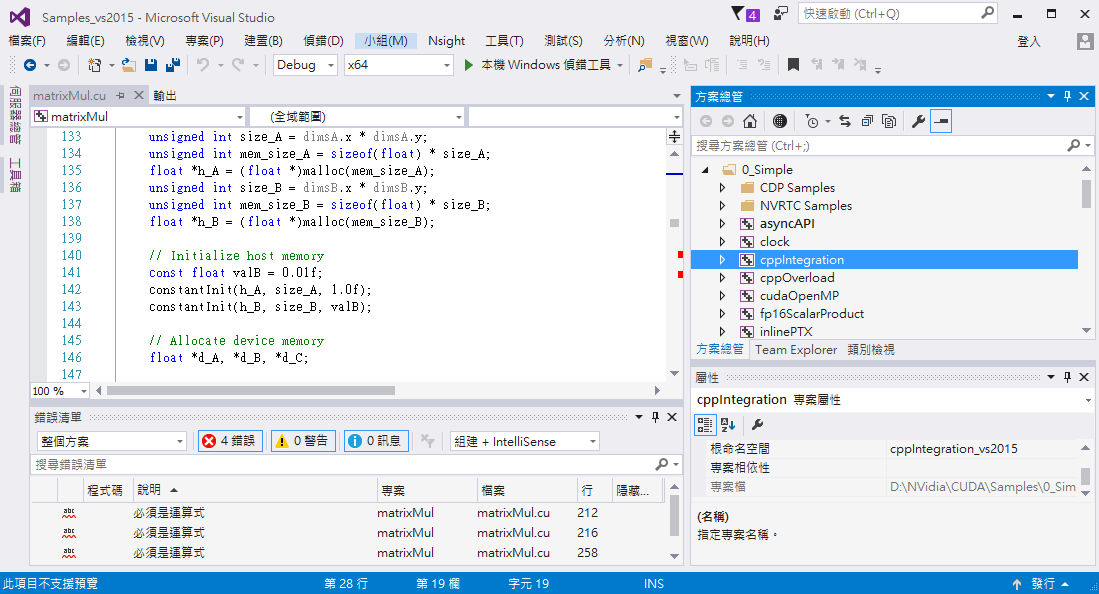
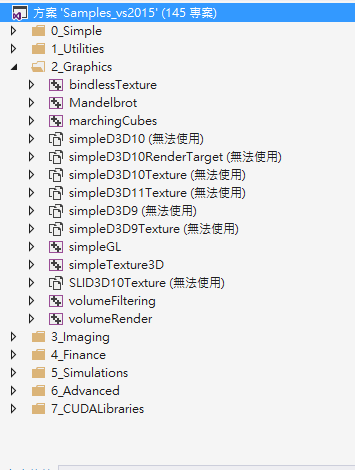
用VS2015開啟Samples_vs2015.sln方案,編譯時會有許多錯誤,這是因為原本在Windows 7 之前的Direct X SDK須另外安裝,但是在Windows 8之後Direct SDK已經內建在Windows SDK裡面,前面雖然已安裝Windows 10 SDK了,但是並不支援Direct X 11之前的版本。我寫CUDA是為了之後做平行處理,因此直接將這些範例卸載,即順利完成編譯:
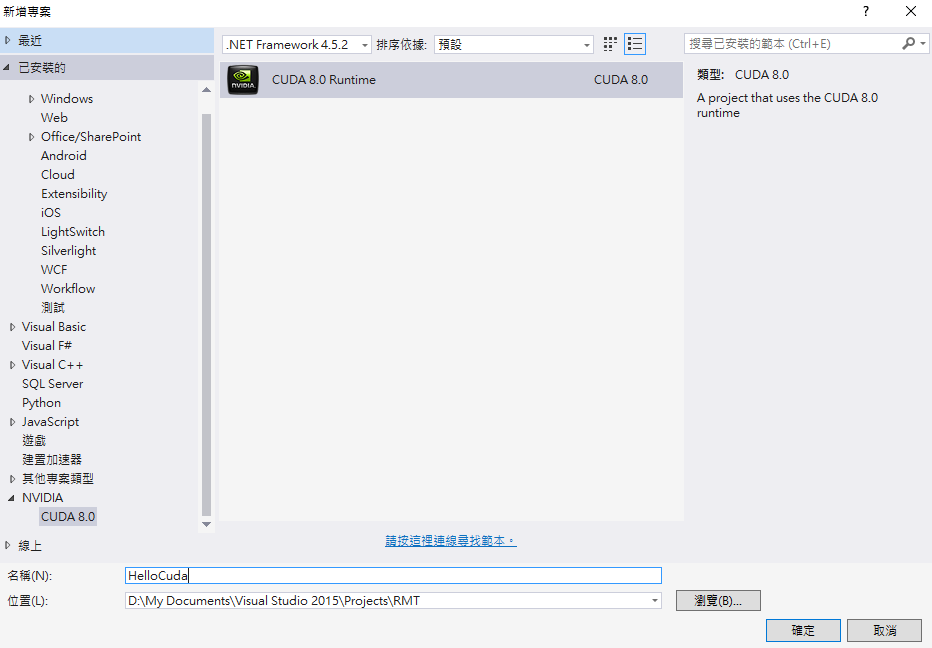
在範例專案中,可以看到副檔名為 cu 的檔案,這其實是c++的語法,只是它會呼叫cuda的編譯器來進行編譯。先建立一個HelloCuda專案來試試。新增NVidia CUDA 8.0 Runtime專案:
完成後專案內的檔案只有一個kernel.cu檔:
打開專案屬性畫面,可以設定要產生的檔案為EXE或其他DLL、LIB等類型。這裡因為是C++語言,因此如果要給其他語言使用,須做其他處理(例如 C# 的 DLL Import)。在這裡是直接產生執行檔:
點選kernel.cu檔,進入程式編輯,可看到程式碼如下:
|
#include "cuda_runtime.h" #include "device_launch_parameters.h" #include <stdio.h> cudaError_t addWithCuda(int *c, const int *a, const int *b, unsigned int size); __global__ void addKernel(int *c, const int *a, const int *b) { int i = threadIdx.x; c[i] = a[i] + b[i]; }
int main() { const int arraySize = 5; const int a[arraySize] = { 1, 2, 3, 4, 5 }; const int b[arraySize] = { 10, 20, 30, 40, 50 }; int c[arraySize] = { 0 };
// Add vectors in parallel. cudaError_t cudaStatus = addWithCuda(c, a, b, arraySize); if (cudaStatus != cudaSuccess) { fprintf(stderr, "addWithCuda failed!"); return 1; }
printf("{1,2,3,4,5} + {10,20,30,40,50} = {%d,%d,%d,%d,%d}\n", c[0], c[1], c[2], c[3], c[4]);
// cudaDeviceReset must be called before exiting in order for profiling and // tracing tools such as Nsight and Visual Profiler to show complete traces. cudaStatus = cudaDeviceReset(); if (cudaStatus != cudaSuccess) { fprintf(stderr, "cudaDeviceReset failed!"); return 1; }
return 0; } // Helper function for using CUDA to add vectors in parallel. cudaError_t addWithCuda(int *c, const int *a, const int *b, unsigned int size) { int *dev_a = 0; int *dev_b = 0; int *dev_c = 0; cudaError_t cudaStatus;
// Choose which GPU to run on, change this on a multi-GPU system. cudaStatus = cudaSetDevice(0); if (cudaStatus != cudaSuccess) { fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?"); goto Error; } // Allocate GPU buffers for three vectors (two input, one output) . cudaStatus = cudaMalloc((void**)&dev_c, size * sizeof(int)); if (cudaStatus != cudaSuccess) { fprintf(stderr, "cudaMalloc failed!"); goto Error; } cudaStatus = cudaMalloc((void**)&dev_a, size * sizeof(int)); if (cudaStatus != cudaSuccess) { fprintf(stderr, "cudaMalloc failed!"); goto Error; } cudaStatus = cudaMalloc((void**)&dev_b, size * sizeof(int)); if (cudaStatus != cudaSuccess) { fprintf(stderr, "cudaMalloc failed!"); goto Error; } // Copy input vectors from host memory to GPU buffers. cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice); if (cudaStatus != cudaSuccess) { fprintf(stderr, "cudaMemcpy failed!"); goto Error; } cudaStatus = cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice); if (cudaStatus != cudaSuccess) { fprintf(stderr, "cudaMemcpy failed!"); goto Error; } // Launch a kernel on the GPU with one thread for each element. addKernel<<<1, size>>>(dev_c, dev_a, dev_b); // Check for any errors launching the kernel cudaStatus = cudaGetLastError(); if (cudaStatus != cudaSuccess) { fprintf(stderr, "addKernel launch failed: %s\n", cudaGetErrorString(cudaStatus)); goto Error; } // cudaDeviceSynchronize waits for the kernel to finish, and returns // any errors encountered during the launch. cudaStatus = cudaDeviceSynchronize(); if (cudaStatus != cudaSuccess) { fprintf(stderr, "cudaDeviceSynchronize returned error code %d after launching addKernel!\n", cudaStatus); goto Error; } // Copy output vector from GPU buffer to host memory. cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost); if (cudaStatus != cudaSuccess) { fprintf(stderr, "cudaMemcpy failed!"); goto Error; } Error: cudaFree(dev_c); cudaFree(dev_a); cudaFree(dev_b); return cudaStatus; } |
從C/C++進入點main() 開始追蹤,可看到它是在計算c[]=a[]+b[]。addWithCuda()函數做的事情是:
1. 呼叫cudaSetDevice(0)選擇要運算的顯卡編號。
2. 呼叫cudaMalloc(),在顯卡上分配記憶體給dev_a、dev_b、dev_c整數陣列。
3. 呼叫cudaMemcpy()把主記憶體的a、b、c整數陣列資料搬進顯卡記憶體。
呼叫addKernel<<<1, size>>>(dev_c, dev_a, dev_b)計算陣列相加。在這裡可以看到 SIMT (single instruction multi threads) 的計算,nVidia 讓這些執行緒可由程式控制,用群組的方式讓一堆執行緒執行相同的指令。nVidia將程式執行分成核心(kernel)、網格(grid)、區塊(block)與執行緒(thread)四個階層,透過內建變數來辨識每個執行緒,基本的內建變數如下,它們只可以使用在 kernel 的程式碼中:
uint3 gridDim:網格大小 (網格包含的區塊數目)
uint3 blockIdx:區塊索引 (區塊的ID)
uint3 blockDim:區塊大小 (每個區塊包含的執行緒數目)
uint3 threadIdx:執行緒索引 (執行緒的ID)
其中 uint3 為 3D 的正整數型態:
struct uint3{
unsigned int x,y,z;
};
在這裡可以看到addKernel()只使用到threadIdx來取得執行緒編號:
|
__global__ void addKernel(int *c, const int *a, const int *b) { int i = threadIdx.x; c[i] = a[i] + b[i]; } |
在 CUDA 中呼叫 kernel 函式的語法多了延伸的語法來指定網格和區塊大小:
|
addKernel<<<1, size>>>(dev_c, dev_a, dev_b); |
最後再呼叫cudaMemcpy()把計算結果搬回主記憶體c陣列,即完成平行計算。
參考資料:
[1] “An Even Easier Introduction to CUDA”, https://devblogs.nvidia.com/parallelforall/even-easier-introduction-cuda/
[2] “CUDA程式設計 II -- SIMT概觀”,http://philip.pixnet.net/blog/post/25478362-%5Barticle%5D%5Bcuda%5D%E8%BD%89%E9%8C%84%E2%80%A7cuda%E7%A8%8B%E5%BC%8F%E8%A8%AD%E8%A8%88-ii----simt%E6%A6%82%E8%A7%80

 留言列表
留言列表
